VGGT:3秒生成3D模型!牛津大学与Meta的“视觉革命”
近期,牛津大学 VGG 与 Meta AI 团队联合发布的最新研究 VGGT,简直是要在3D视觉领域掀起一场“革命”啊!
VGGT,全称Visual Geometry Grounded Transformer,是个基于纯前馈Transformer架构的通用3D视觉模型。别看它名字长,功能可不含糊——单张、多张甚至上百张图像,它都能轻松搞定,直接推理出相机参数、深度图、点云及3D点轨迹等核心几何信息。而且,这一切都在一次前向推理中完成,无需任何后处理优化,速度快到飞起!

传统3D重建依赖束调整等优化方法,计算复杂、耗时漫长,堪称“慢工出细活”, 还得反复迭代。VGGT呢?直接摒弃了这一繁琐过程,采用纯前馈设计,结合大规模3D标注数据与Transformer架构,一次前向传播就能搞定全部几何推理任务。这效率,简直了!
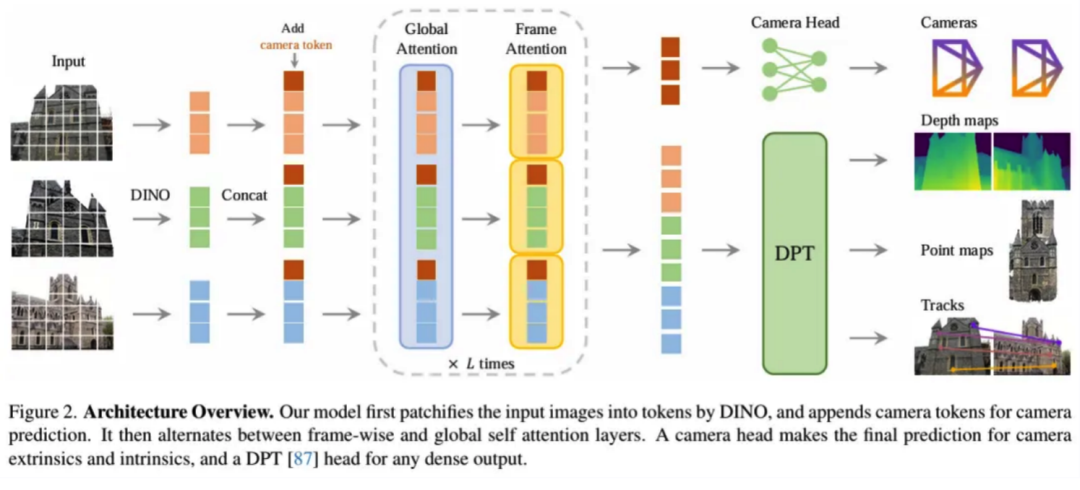
更厉害的是,VGGT的泛化能力超强。训练时只用2-24帧数据,测试时却能轻松处理超过200帧的输入。而且,它还能精准重建梵高油画等非真实场景的几何结构,处理无重叠视图或重复纹理的极端案例也是游刃有余。这能力,简直让人叹为观止!

当然啦,VGGT的潜力可不止于此。尽管它从未接受过单图训练,但在单目任务中的表现也是相当出色。这足以证明,VGGT作为通用3D基础模型的潜力是巨大的。
VGGT用最“简单粗暴”的架构,撕开了3D基础模型的新赛道——在这里,AI不仅理解世界,还能一键重建它。
大家感兴趣的赶紧去试试吧!(需要科学上网)
代码链接:https://github.com/facebookresearch/vggt
演示平台:https://huggingface.co/spaces/facebook/vggt
更多AI知识请前往脑洞大开AI实验室官方网站
https://www.ai360labs.com
使用脑洞大开AI实验室AI对话功能,可访问
https://www.ai360labs.com/playground/chatService/new
点击底部分享、赞和在看,把好内容传递出去