当AI遇上《我的世界》:一场高中生与科技巨头的创意对决

在AI技术飞速发展的今天,如何评估AI模型的能力成为了一个热门话题。传统的AI基准测试(AI benchmarking )方法已经显得力不从心,开发者们开始寻找更具创意的评估方式。而一名高中生Adi Singh,竟然通过《我的世界》(Minecraft)这款游戏,为AI模型搭建了一个全新的竞技场。
从《我的世界》到AI竞技场
Adi Singh开发的网站Minecraft Benchmark(简称MC-Bench),将AI模型置于《我的世界》的虚拟世界中,让它们根据提示进行建筑创作。用户可以投票选出他们认为更好的作品,只有在投票后才能知道哪个AI模型完成了哪项任务。这种创新的方式不仅让AI能力的评估变得直观有趣,也让普通人能够轻松参与其中。
为什么选择《我的世界》?Adi Singh解释道,即使是没有玩过《我的世界》的人,也能轻松判断哪个“菠萝”的方块建筑更具表现力。通过这种方式,AI的进步变得更加直观,普通人也能轻松理解。
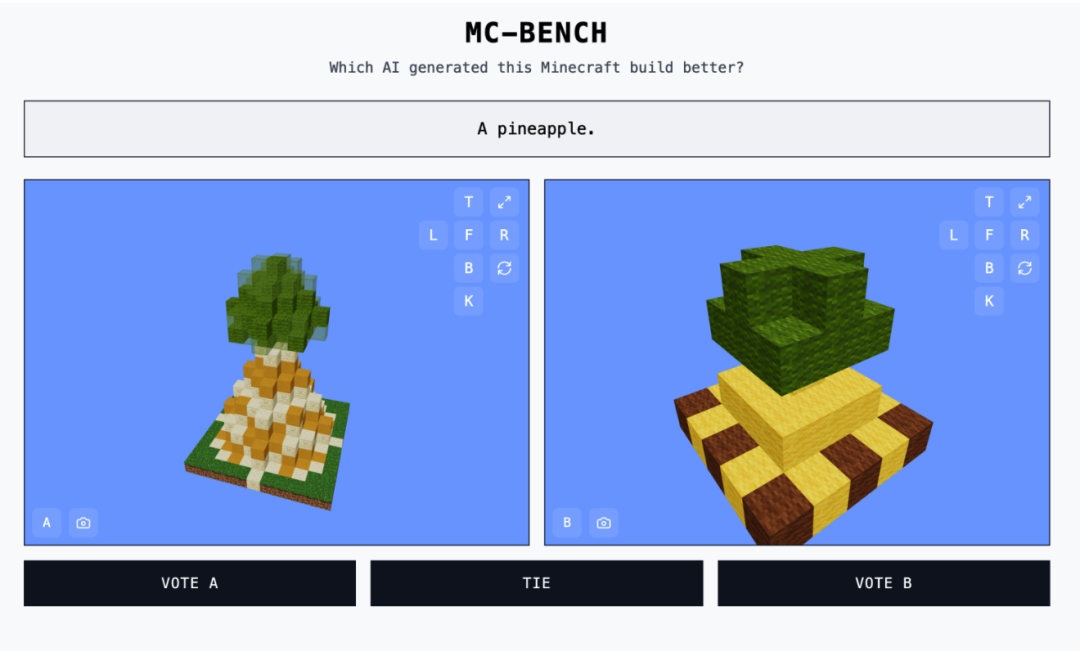
AI的“创造力”大比拼
MC-Bench的挑战任务看似简单,比如“建造一个雪人”或“在沙滩上搭建一座热带小屋”,但背后却隐藏着复杂的编程逻辑。AI模型需要生成代码来完成这些任务,而用户则通过直观的建筑效果来评判AI的表现。这种方式不仅让技术变得更加亲民,也为AI模型的创造力提供了一个全新的测试平台。
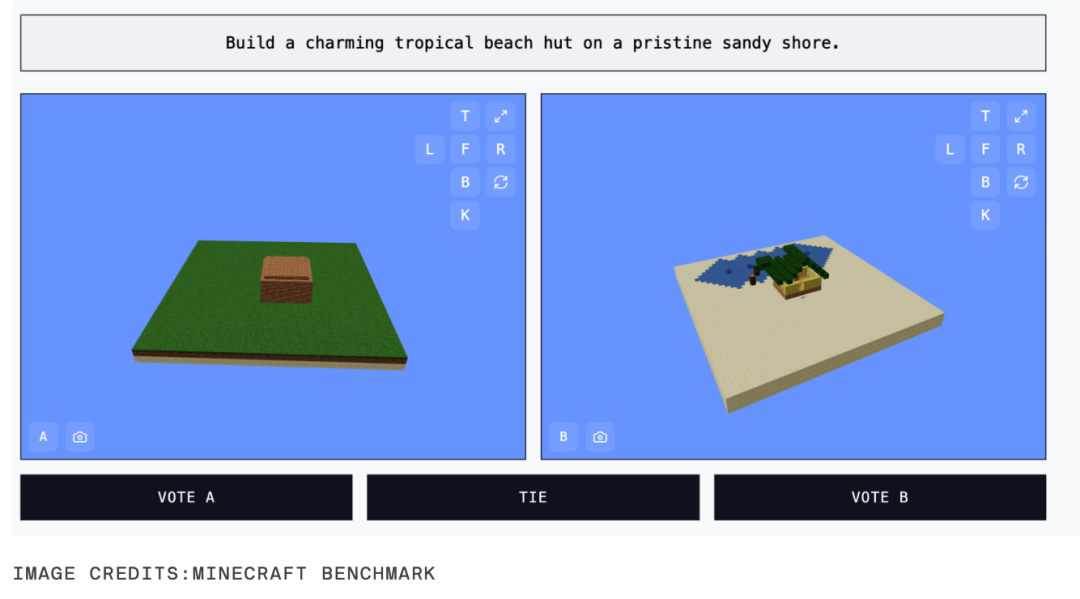
目前,MC-Bench的团队由八人组成,项目得到了Anthropic、Google、OpenAI和阿里巴巴等科技巨头的支持。虽然这些公司并未直接参与项目,但它们为MC-Bench提供了AI模型的使用权限。
简单任务到复杂挑战
MC-Bench目前主要进行一些简单的建筑任务,回顾从GPT-3时代以来的AI发展历程。但展望未来,可以扩展到更复杂的计划和目标导向任务。游戏作为一种测试媒介,不仅比现实生活更安全,也更容易控制,因此是测试AI代理推理能力的理想选择。
这并不是唯一一个将游戏作为AI测试平台的案例。像《精灵宝可梦 红/绿》、《街头霸王》和《超级马里奥兄弟》等游戏,也都被用来测试AI的能力。这些游戏不仅为AI提供了一个可控的环境,也让我们能够更直观地看到AI的进步和局限。

困境与突破
传统的AI基准测试存在局限性。许多测试方法让AI在特定领域表现优异,但在实际应用中却显得力不从心。例如,OpenAI的GPT-4在LSAT考试中表现优异,但在回答“草莓”这个词中有多少个“R”时却犯了错误。Anthropic的Claude 3.7 Sonnet在软件工程基准测试中取得了62.3%的准确率,但在玩《精灵宝可梦》时却不如一个五岁孩子。
结语
通过《我的世界》这个虚拟世界,我们不仅能看到AI的创造力,也能更直观地感受到技术的进步。或许,未来的AI基准测试将不再局限于枯燥的代码和分数,而是通过更多有趣的方式,让我们看到AI的无限可能。
如果你对AI与游戏的结合感兴趣,不妨访问https://mcbench.ai/,亲自体验这场科技与创意的碰撞。
内容来源:https://techcrunch.com/
图片来源:Minecraft Benchmark
如果你喜欢这篇文章,欢迎分享给你的朋友,并关注我们的公众号【脑洞大开AI实验室】,获取更多关于科技与文化的深度内容。
更多AI知识请前往脑洞大开AI实验室官方网站
https://www.ai360labs.com
使用脑洞大开AI实验室AI对话功能,可访问
https://www.ai360labs.com/playground/chatService/new
点击底部分享、赞和在看,把好内容传递出去
 bilibili
bilibili 企业微信群
企业微信群 微信客服
微信客服 公众号
公众号